
Si Twitter no refleja la sociedad, ¿por qué los científicos hurgan en tus datos?

“No hay preguntas. ¡Es como un planeta por descubrir!”, describe, vía Skype y desde su casa en Nueva York, Lev Manovich. “Todo lo que creas sobre cómo hacer una investigación está mal. Si empiezas con preguntas, está mal. Antes había que plantear una hipótesis, recoger datos y responderla. Ahora tenemos los datos: vamos a jugar con ellos y que la imaginación sea nuestro límite”.
Manovich es profesor de informática en la Universidad de la Ciudad de Nueva York y habla entusiasmado: tiene entre manos una base de datos gigante y está empezando a explorarla. Lo hace junto a Mehrdad Yazdani y Jay Chow, un científico y un desarrollador web de San Diego, en un proyecto cuya única pregunta es: ¿podemos medir la felicidad en las ciudades de forma diferente a la tradicional? “Los índices de bienestar se basan en variables externas como la educación, la salud o el medioambiente. Y las únicas variables internas (las que preguntan directamente a la gente) vienen de encuestas”, asegura. “Están temporal y espacialmente limitadas”.
Su solución es el 'big data'. En concreto, todas las fotografías que se han subido a Twitter desde 2011. “Los usuarios se expresan en las redes sociales y desarrollamos análisis de sentimientos visual”, continúa. No es la primera vez que este equipo analiza imágenes - ya visualizaron 2,3 millones de fotografías de Instagram y estudiaron la sociología de los 'selfies' - pero sí que la base de datos es tan valiosa. Procede de la propia fuente, porque es Twitter quien les ha dado acceso gratuito a todo su historial.
Estudios sobre redes sociales hay muchos, pero siempre los hacen otros o dependen de información con restricciones. La semana pasada hablábamos de cómo unos investigadores en Cataluña diseccionaron BitTorrent sacando la información con su propio método (pedir a los usuarios que instalaran un 'plugin' para descargar más rápido a cambio de monitorizar su comportamiento) y de cómo la importancia de su estudio, más allá de las conclusiones, estaba en aquellos datos.
Pero BitTorrent no había cedido nada. Es lo habitual: una cosa es que una empresa tenga herramientas para ver tendencias, otra cosa es que alguien las extraiga con sus métodos, y otra más allá que la compañía diga: aquí tienes. Este archivo gigante con todos los datos que se han generado dentro de mi red es tuyo, en nombre de la investigación.
Es justo lo que ha hecho Twitter. “En los últimos dos años, las empresas se han concienciado mucho más de qué información liberar en sus APIs - entre otras cosas, porque otros pueden construir servicios mejores usándolas. Pocas tienen base de datos histórica, y si la tienen la usan con fines comerciales”, continúa el profesor. “Twitter no nos ha dado acceso a una muestra de datos, sino a todo”.
Hasta hace poco, la red social daba acceso al archivo histórico, a través de herramientas asociadas, a quien pudiera pagarlo (normalmente, empresas que monitorizan lo que se dice en internet para ver cómo atrapar al consumidor). Pero a Twitter llegaron peticiones de académicos que también necesitaban acceder.
Con casi una década de información acumulada quieren “estudiar el pasado” y Twitter, que sabe el valor que la suya genera, anunció en abril becas para dar sus datos a equipos de investigación. De las más de mil solicitudes, ganaron seis: además de los investigadores de la felicidad ciudadana, proyectos para estudiar las campañas de detección de cáncer o la respuesta social frente a catástrofes como las inundaciones en Yakarta.
¿Es legal?
Twitter no es la primera red social que comparte sus datos con universidades. En mayo, internet se escandalizó porque Facebook había “manipulado” sus emociones. A estas alturas sabrás que el muro de Facebook no se ordena cronológicamente, sino que intenta mostrar lo “más relevante” excepto cuando le da por experimentar, que saca lo que le da la gana. Durante una semana, en enero de 2012, la red hizo cambios en los muros de 689.003 usuarios y mostró a un grupo contenido positivo y a otro negativo, comprobando que los primeros publicaban más 'posts' positivos y viceversa y concluyendo que las emociones en red se contagian. El experimento fue publicado en un 'paper' que firmaron científicos de Facebook e investigadores de la universidad de Cornell.

A los usuarios no les gustó enterarse de que su casa digital es un laboratorio de pruebas, pero otro punto interesante fue este debate: si Facebook había hecho el estudio con la Universidad, ¿quién lo había pagado? ¿Era ético? ¿Y legal? Como explicó el jurista TIC Jorge Morell en HojaDeRouter.com, “Facebook dice que al ser una entidad privada no tenía que pasar por el comité de ética. La universidad de Cornell añade que, como ellos simplemente trabajaron sobre unos datos que Facebook ya tenía, se trata de una excepción a la necesidad de todo el proceso legal”.
Y esta vez ha pasado casi desapercibido, pero el viernes se supo que en 2012, antes de las elecciones estadounidenses, Facebook experimentó durante tres meses con los muros de 1,9 millones de usuarios para ver cómo afectaba la información de su muro a la participaciónexperimentó durante tres meses con los muros de 1,9 millones de usuarios para ver cómo afectaba la información de su muro a la participación. En esta ocasión, su estudio (que se hizo dentro del equipo científico de la empresa, no con la Universidad) descubrió que si el muro muestra más noticias, la persona está más dispuesta a votar.
Poco después del experimento de las emociones, Facebook modificó sus documentos legales para añadir que los datos de los usuarios podrán utilizarse con fines de investigación.
El pasado 8 de septiembre, Twitter también cambió su política de privacidad. Donde antes había un “Twitter archiva tweets con fines históricos” ahora hay un detallado “su información pública se entrega [...] a instituciones como universidades y agencias públicas de la salud que analizan la información para observar tendencias y comentarios”. Morell añade que “toda la parte final es nueva y contempla de forma expresa esa opción. Es probable que el cambio se haya hecho con vistas a iniciativas de ese tipo”.
¿Es representativo?
Twitter sabe que lo que sucede dentro de su red social tiene valor. Para que el mundo se entere, ha dejado que otros, seleccionados por la empresa, lo exploren.
“He hablado con gente de Twitter y creo que abren los datos porque tienen filosofía 'open-source' y quieren compartir sus datos sociales con investigadores”, considera Yadzani. “Podrían abrirlos a todo el mundo, sí, pero hay límites y puede ser peligroso. Así que se lo dan a unos pocos, responsables, pero pocos. Lo interesante será ver qué crea la gente”.
¿Le gustaría que otras empresas siguieran sus pasos? “Cuanto más datos tenga, más puedo analizar. ¡No me voy a quejar! Y creo que pasará en el futuro. Los datos crecen exponencialmente y a las empresas les interesa abrirlos. Es un reto porque el 90% del trabajo es limpiar y organizar los datos y que el 10% restante, de análisis, es muy complicado. Por eso necesitas diferentes ojos para ello”. Y por eso, empresa, se lo das a la ciencia.
“Normalmente recibes muestras, pero ¿qué pasa cuando puedes estudiar la sociedad y acceder a cada uno de los datos y expresiones humanas en las redes sociales?”, apunta Manovich. “Es una reinvención de la ciencia social. No es una muestra, es todo”.
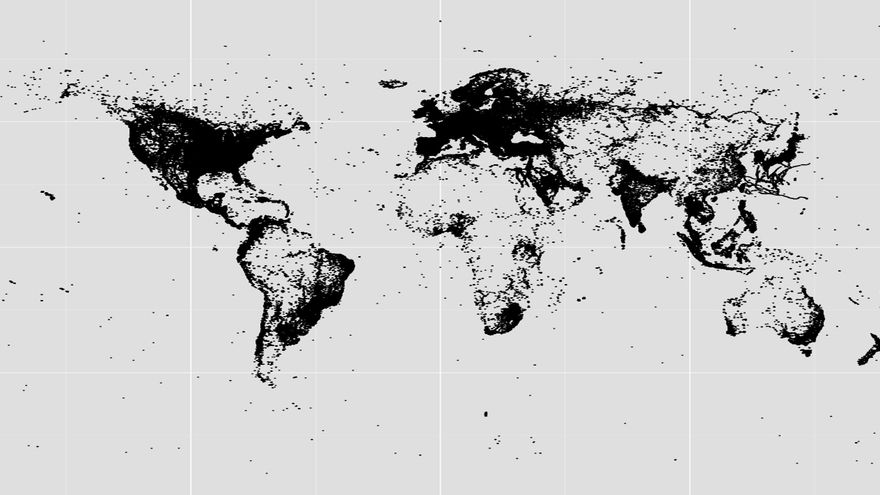
¿Todo? “Miles de millones de personas de todo el mundo permanecen en la periferia del 'big data'. Su información no se recolecta o analiza porque no participan en actividades que el 'big data' está diseñado para capturar. Así, sus preferencias y necesidades corren el riesgo de ser ignoradas por gobiernos e industria privada que usan analítica y datos para diseñar políticas y mercados. El 'big data' no es sólo una amenaza a la privacidad, también puede derivar en exclusión”.
Este ensayo de Standford Law Review piensa en el 'antidata', o lo que los estudios basados en 'data' no ven. Pero los científicos de nuestra historia son de momento más optimistas: “Tampoco todo el mundo está incluido en las encuestas. Sí, la gente que participa en Twitter es diferente, pero para mí la principal pregunta es cómo la gente se representa a sí misma con esta herramienta, las fotografías en Twitter, de la que encontraremos sus limitaciones. Quizá encontremos que la representación es una limitación”.
-----------------------
Las imágenes que aparecen en este artículo son propiedad de Selfiecity, The Happiness of Cities y Marketingfacts
